你好,SLAM2.0.
在2016年,发表于TRO的论文《Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age》中,回顾了SLAM(同时定位与建图)领域的一个经典问题:“SLAM问题是否已经得到解决?”时至今日,距离这一讨论已经过去了八年。随着SLAM2.0概念的提出,我们在2024年重新回顾这个问题,并将围绕以下两个核心问题展开讨论:1. 什么是SLAM?2.我们将如何理解SLAM2.0?
前言
在1986年的IEEE Robotics and Automation Conference 大会上,研究者(Hugh Durrant-Whyte,Peter Cheeseman,Jim Crowley,Raja Chatila, Oliver Faugeras Randal Smith)们渴望将概率方法引入到机器人和AI领域,他们希望移动机器人能通过板载传的感器实现在未知环境下的自身定位与对环境的描述。像传说中的故事一样,他们才思泉涌,他们讨论激烈,纸巾和餐巾纸上都记录着他们对于移动机器人定位的idea和对环境构建的思考,而这次会议也被SLAM学者们广泛的认为是有关SLAM的第一次公开讨论的记录。即时定位与建图(Simu)这种不用依赖外置环境布置(如GNSS),仅需依靠机器人自身传感器的定位与建图的算法开始成为机器人研究领域的宠儿之一。
SLAM 1.0时代
结合论文《Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age》的定义,我这里将SLAM 1.0总结为三个时期:古典时期(1986-2004),算法时期(2004-2015)和应用时期(2016-2022)。
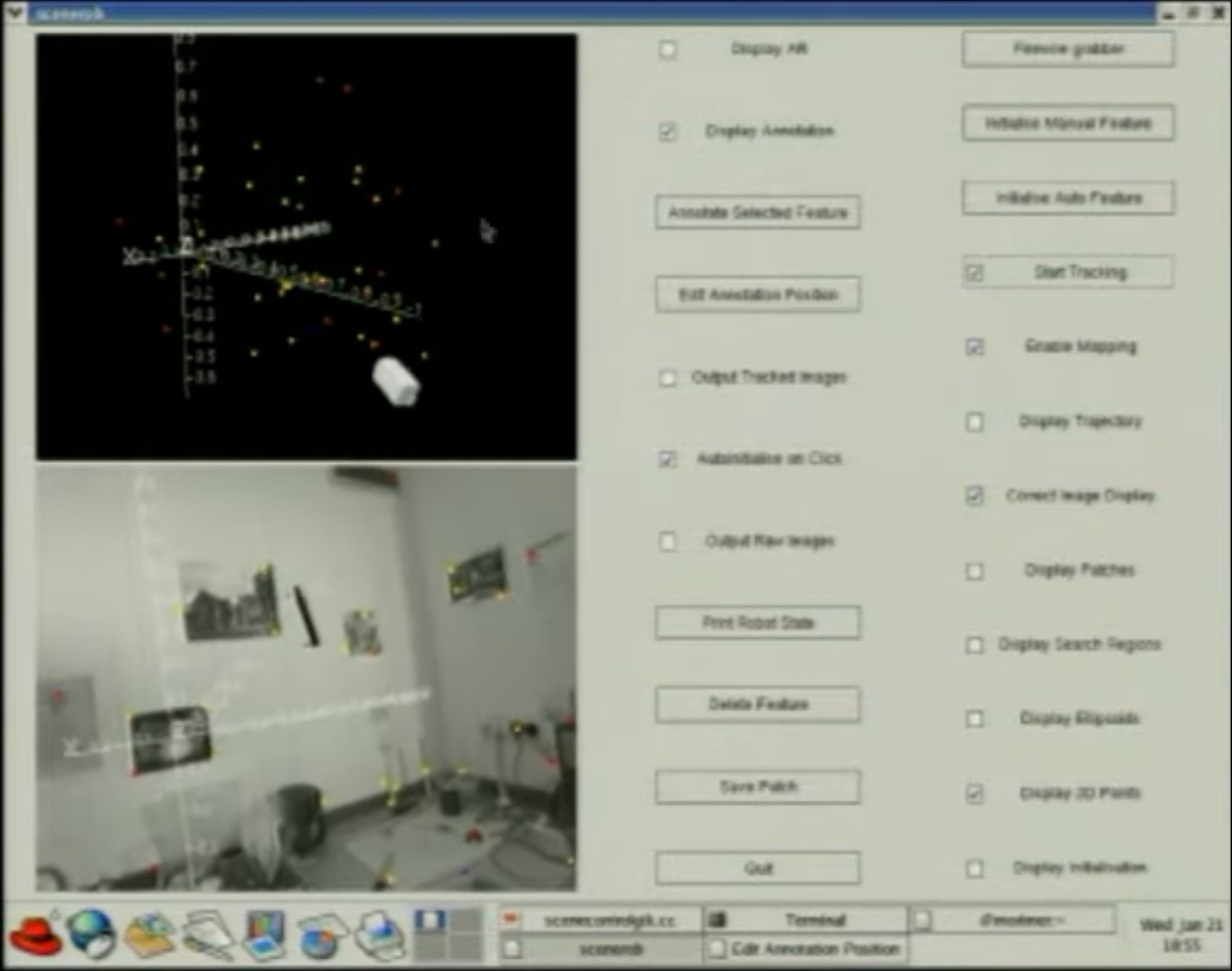
在古典时期,人们在探索不同算法的可行性:当时的研究者们将SLAM问题都以概率表示,尝试通过不同的概率模型来解决遇到的问题(如扩展卡尔曼滤波(EKF)和粒子滤波(RBPF)算法等)。在这一时期时,人们主要是探索机器人能不能用板载传感器来实现机器人的定位:研究者们像医生一样,不断地给机器人装上不同的传感器。单线激光雷达、视觉传感器和声呐这些在当时看来昂贵的硬件仿佛是人类给机器人后天赋予的视觉和听觉器官,助力机器人探索世界的奥秘。可能因为年代久远,硬件等计算资源的匮乏,这一时期的论文算法理论创新不断,但实践应用的展示却不多。当然也有诸如像Mono-SLAM这样的经典算法出现,但SLAM更多的像一个襁褓里的婴儿,让研究者们在实验室里精心伺候。定位与建图,这俩相辅相成的模块也在这一时期被人们广泛地定义为SLAM的前后端,一直影响到如今的SLAM算法。
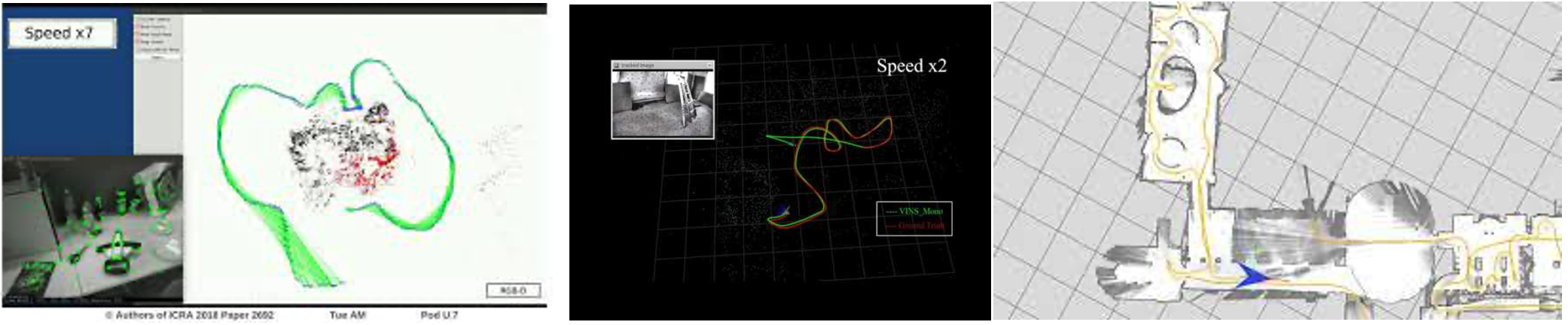
在算法时期,人们开始思考从原理上分析SLAM算法:可观性、收敛性和一致性都在这个时期被人们充分讨论,与此同时,开源软件也不断开始涌现。open-slam.org网站的创立,以及上面贡献的经典算法都极大的加速了SLAM算法的出现和研究。这一时段的中后期,随着硬件的加速,研究者们也不局限于实验室场景,Get out of my lab的呼声开始在论文中出现:论文不仅仅是有精确的数值,往往也会配上酷炫的demo。除了本身的定位主题外,重建,避障,探索等任务也逐步与SLAM算法相结合。每一次的学术会议上,SLAM都像一个两三岁蹒跚学步的小孩,被长辈亲戚(研究者)们拉到台前来表演各种各样的节目。除了芯片等计算机硬件革新外,这一时期的传感器也在不断变化:深度相机、红外传感器、3D激光雷达都开始涌现,原本的上一时期主流的传感器们(单线激光雷达、视觉相机甚至惯性传感器等)价格也在不断降低,为SLAM落地提供了良好的硬件基础。诸如像西班牙萨拉戈萨大学开源的ORB-SLAM和谷歌开源的Cartographer更是分别加速了AR和移动机器人领域的发展。落地的可能性更是进一步激起了研究者的热情,学术到财富自由,似乎是那么的接近。但这一时期,人们也产生了疑问,从demo来看,SLAM似乎效果已经很好了,那SLAM这个问题是不是已经解决了?

如果对于一个SLAM算法的要求是漂移率小于其本身轨迹长度的0.5%的话,SLAM算法似乎是已经解决了。剩下的似乎只是些小修小补的工作:标定如何更准一些,运算如何更快一点,不同数据集的benchmark(TUM/EuROC/KITTI)上如何刷的更高一点?SLAM似乎正式开始进入了应用纪元。在这一时期的早期(2016-2019),VC(投资人们)迫不及待地给SLAM的研究者们投入大量的金钱,期待他们将自己的学术成果变现。但SLAM表现的却像一个突然被拉到年会上表演的幼儿园宝宝,紧张不行且错误不断。这一时期的会议上充斥着各种领域SLAM的应用成果。他们分享着之前SLAM算法在落地时的失败,以及自己的改进。但并没有任何一个算法能表现出全能,SLAM像中国古文中的”仲永”一样,在给无数人期待的同时也带给了无数人的失望。但这一时期不断出现的数据集也像不断变难得考卷,场景越来越大,定位要求越来越高。SLAM像一个倔强的小学生,在研究者的搀扶下不断地从跌倒的坑中爬起,继续一路向前。像之前的任何时期一样,研究者们也在搜索新的传感器能给这一算不断赋能。2020年后,3D激光雷达、惯性传感器成本上的降低以及新的视觉传感器(如事件相机和360相机)的出现,都给SLAM研究者们带来了不一样的惊喜:无论是精度还是鲁棒性,SLAM算法都展现出了不错的性能。其中3D激光雷达带来的惊喜让SLAM研究者们又一次受到了投资人们的青睐,无数的三维扫描和重建的公司开始出现。SLAM似乎又是过年时亲戚长辈们最疼爱的小孩,但人们还没来得及高呼一般情况下,SLAM问题已经被解决的时候,意外出现了:隔壁“邻居家的孩子”深度学习来串门了。
令人讨厌的邻居家孩子-深度学习
实际上这不是深度学习第一次来串门了:2012年,随着GPU的发展,以及深度学习在CV领域的大显身手。越来越多的研究者们也开始尝试用深度学习来解决SLAM中的任务:研究者们尝试用深度学习来进行实现端到端的任务实现。深度学习就像隔壁地主家的傻儿子一样:花大价钱(买GPU)请了教书先生一对一辅导(构建训练集),但每次都是一看就会(测试机精度高),一做就错(实际使用一团糟)。但同时,他们也宣称:SLAM解决不了的问题我都能解决(失效场景下,的确深度学习能大力出奇迹)。SLAM作为穷人家的小子只能默默不吭声:每次考试的时候(顶会)都坐的离深度学习远一点,你比你的,我比我的,无论你怎么说,我实际效果都似乎更好一点,并且我更好一点。但是2018年后,SLAM突然发现,深度学习不一样了:它们不在执着于端到端的任务表现,而更关注SLAM失败的地方,不断学习和提升。它们像武侠剑客中的高手一样,不断学习SLAM算法中的失败案例,探索出不一样的解决方案(如Superpoint、Superglue等)。SLAM则记住了他们的方案,融合到自身去变强(将深度学习模型部署到SLAM中去:像GCNV2-SLAM,将SuperPoint方案融合到ORB-SLAM算法中)。SLAM像一个抄作业的小学生一样,飞速地抄着深度学习做出的正确答案:就这么抄了3年,到了2021年,DROID-SLAM的出现。SLAM发现坏了,我成替身了:端到端的在定位能力上的展现让SLAM冷汗直冒,以往一直被SLAM嘲弄的泛化性问题,在这时似乎也不复出现,并且端到端的可微的特性也让它能快速的跟上应用的发展(如NeRF-SLAM即DROID-SLAM的地图NeRF化)。令SLAM心烦的事情还没结束时,另一个令SLAM的消息来了:特斯拉FSD算法的出现让SLAM意识到定位似乎不再需要SLAM了。SLAM像一个落寞的商女站在2022年的结尾不知道往哪里走,只能在嘴里嘟囔着:我比较便宜。SLAM似乎也得尝试做一些改变了。
SLAM 2.0时代

我第一次听到SLAM2.0的名词时是殷鹏来上交E谷做报告的时候:抛出了一个很重要的观点:对SLAM的期待还仅仅在定位上是不够的。都2023年了,较真那1cm,2cm的优势,有意思吗?换句话来说,SLAM的评估指标变了。之前对SLAM的研究中,人们更多的做法是让机器人持有待测的传感器,行走一段轨迹,记录下来高成本传感器所采集到的轨迹值作为轨迹真值。评估估计轨迹值与真值的误差,作为衡量SLAM算法好坏的指标。但是现在,人们对SLAM的期望更多的是能不能支持人们对机器人的任务要求:可能研究者们不再具体要求机器人发出的要求是走到桌子前,而不是走到桌子前5cm,正中心斜对角30°处。并且SLAM研究者不再想“搀扶”着机器人出门,更多地想着机器人能依据任务的需求自主行动,自主评估。如果给这个时期的SLAM定义,可能人们更多希望它是从幼儿园走入小学,能自主的判断出自己前进的方向和道路。
2.0时代的博士生们又能做什么呢?
SLAM2.0时代这个名词对于机器人来说可能是美梦,但对于这个时代的博士生们来说可能更多的是噩梦了。毕竟精度不再是评估指标(意味着审稿人兴趣降低),任务的结合似乎只是老板口中的饼(毕竟学的要更多了,除了SLAM基础,导航,learning缺一不可)。更害怕的是万一隔壁家的孩子深度学习哪一天再弄出一个Robotics-GPT又把整个领域给端了,那读博期间学的似乎都是落后技术了。对此,建议如下:
- 目前SLAM算法精度评估都还是在一般情况下,传感器退化场景下的SLAM算法研究依然是一个巨大的topic(强烈建议看看赵世博师兄的SubTMRS Dataset)。
- 依据团队能力的不同,在任务结合上的SLAM算法中也有不同的解决方案:
- 如果你是在地主家(卡多)的孩子:和导师探讨完任务后,就开始尝试深度学习,不停地训,往死了训。大力出奇迹。
- 如果你是在佃户家(传统机器人团队)的孩子:尝试SLAM算法在实际中的使用,从实际出发,发掘应用中的问题,不断创新解决。导师讲道理的话和导师多讨论。同时多留意新型传感器,新型传感器出现时,发挥主观能动性:不要犹豫,直接砸钱投入去买去做,做出成果后再找导师报销。
- 如果你是贫民家(上面俩者都不是导师也很mean)的孩子:一种和导师商量讨论跑路,到各个公司或其他学校团队里实习,做出来成果后面也会挂上导师的名字。另一种就是老子天下第一自己做,没人能阻拦你的成功。如果不行的话,就换方向吧。
- 不要因深度学习大模型时代带来的焦虑,心中永远默念九阳神功的口诀:他强任他强,清风拂山岗。他横由他横,明月照大江。他们大模型再好,也离不开GPU成本的开销。我们SLAM再有诸多不是,我们也有便宜的特点,毕竟又不是不能用。
这是我开启个人blog后的第一篇Blog,很多地方肯定写的不够准确有误,欢迎各位评论与讨论,如果有问题的话,也轻各位轻喷。